Introduction
In previous chapters, we emphasized sampling properties of the sample mean and variance. We also emphasized displays of data in various forms. The purpose of these presentations is to build a foundation that allows us to draw conclusions about the population parameters from experimental data. For example, the Central Limit Theorem provides information about the distribution of the sample mean
In this chapter, we begin by formally outlining the purpose of statistical inference. We follow this by discussing the problem of estimation of population parameters. We confine our formal developments of specific estimation procedures to problems involving one and two samples.
Statistical Inference
In Chapter 1, we discussed the general philosophy of formal statistical inference. Statistical inference consists of those methods by which one makes inferences or generalizations about a population. The trend today is to distinguish between the classical method of estimating a population parameter, whereby inferences are based strictly on information obtained from a random sample selected from the population, and the Bayesian method, which utilizes prior subjective knowledge about the probability distribution of the unknown parameters in conjunction with the information provided by the sample data.
Throughout most of this chapter, we shall use classical methods to estimate unknown population parameters such as the mean, the proportion, and the variance by computing statistics from random samples and applying the theory of sampling distributions, much of which was covered in the previous chapter.
Statistical inference may be divided into two major areas: estimation and tests of hypotheses. We treat these two areas separately, dealing with theory and applications of estimation in this chapter.
To distinguish clearly between the two areas, consider the following examples:
-
A candidate for public office may wish to estimate the true proportion of voters favoring him by obtaining opinions from a random sample of 100 eligible voters. The fraction of voters in the sample favoring the candidate could be used as an estimate of the true proportion in the population of voters. A knowledge of the sampling distribution of a proportion enables one to establish the degree of accuracy of such an estimate. This problem falls in the area of estimation.
-
Now consider the case in which one is interested in finding out whether brand A floor wax is more scuff-resistant than brand B floor wax. He or she might hypothesize that brand A is better than brand B and, after proper testing, accept or reject this hypothesis. In this example, we do not attempt to estimate a parameter, but instead we try to arrive at a correct decision about a pre-stated hypothesis. This falls under hypothesis testing.
Once again we are dependent on sampling theory and the use of data to provide us with some measure of accuracy for our decision.
Classical Methods of Estimation
A point estimate of some population parameter
An estimator is not expected to estimate the population parameter without error. We do not expect
Consider, for instance, a sample consisting of the values 2, 5, and 11 from a population whose mean is 4 but is supposedly unknown. We would estimate
Unbiased Estimator
What are the desirable properties of a “good” decision function that would influence us to choose one estimator rather than another? Let
Definition:
A statistic
is said to be an unbiased estimator of the parameter if
Variance of a Point Estimator
If
Definition:
If we consider all possible unbiased estimators of some parameter
, the one with the smallest variance is called the most efficient estimator of .
The following figure illustrates the sampling distributions of three different estimators,
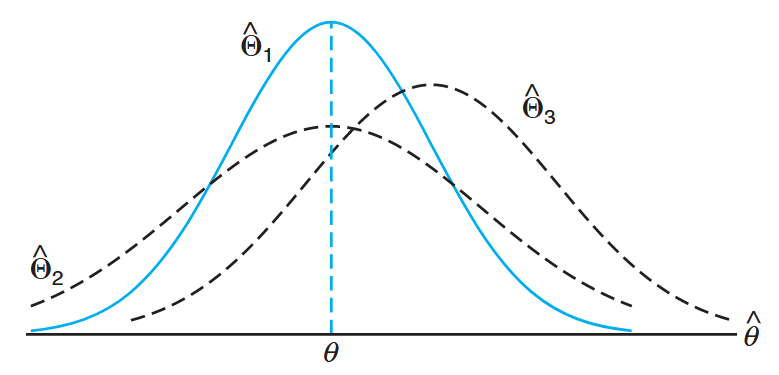
Sampling distributions of different estimators of
. (Walpole et al., 2017).
It is clear that only
For normal populations, one can show that both
Interval Estimation
Even the most efficient unbiased estimator is unlikely to estimate the population parameter exactly. It is true that estimation accuracy increases with large samples, but there is still no reason we should expect a point estimate from a given sample to be exactly equal to the population parameter it is supposed to estimate. There are many situations in which it is preferable to determine an interval within which we would expect to find the value of the parameter. Such an interval is called an interval estimate.
An interval estimate of a population parameter
For example, a random sample of SAT verbal scores for students in the entering freshman class might produce an interval from 530 to 550, within which we expect to find the true average of all SAT verbal scores for the freshman class. The values of the endpoints, 530 and 550, will depend on the computed sample mean
As the sample size increases, we know that
Interpretation of Interval Estimates
Since different samples will generally yield different values of
If, for instance, we find
for
Definition:
The interval
, computed from the selected sample, is called a confidence interval, the fraction is called the confidence coefficient or the degree of confidence, and the endpoints, and , are called the lower and upper confidence limits.
Thus, when
Of course, it is better to be
In the sections that follow, we pursue the notions of point and interval estimation, with each section presenting a different special case. The reader should notice that while point and interval estimation represent different approaches to gaining information regarding a parameter, they are related in the sense that confidence interval estimators are based on point estimators.
In the following section, for example, we will see that
We begin the following section with the simplest case of a confidence interval. The scenario is simple and yet unrealistic. We are interested in estimating a population mean
Despite this argument, we begin with this case because the concepts and indeed the resulting mechanics associated with confidence interval estimation remain the same for the more realistic situations presented later in this section and beyond.
Single Sample: Estimating the Mean
The sampling distribution of
Let us now consider the interval estimate of
Writing
where
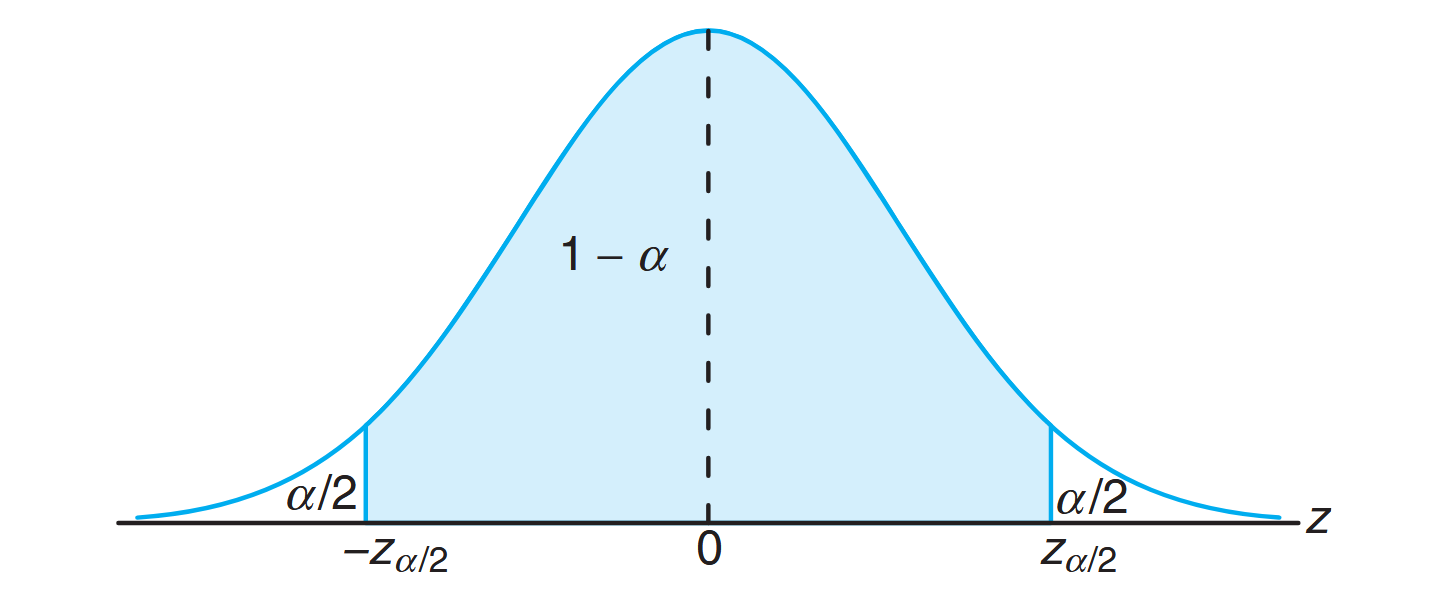
Hence,
Multiplying each term in the inequality by
A random sample of size
Definition:
If
is the mean of a random sample of size from a population with known variance , a confidence interval for is given by where
is the -value leaving an area of to the right.
For small samples selected from nonnormal populations, we cannot expect our degree of confidence to be accurate. However, for samples of size
Clearly, the values of the random variables
Different samples will yield different values of
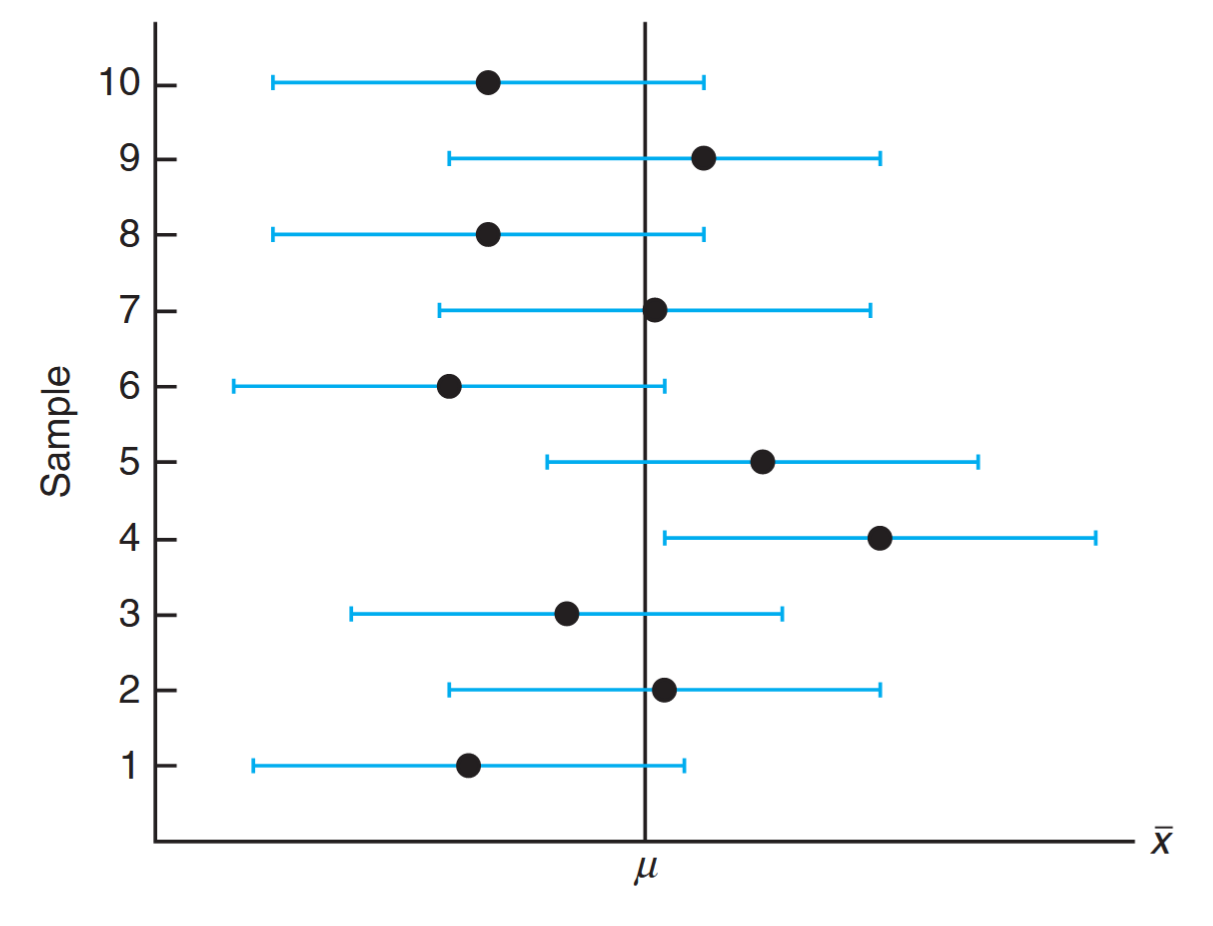
Interval estimates of
for different samples. (Walpole et al., 2017).
The dot at the center of each interval indicates the position of the point estimate
Example: Zinc Concentration
The average zinc concentration recovered from a sample of measurements taken in 36 different locations in a river is found to be
grams per milliliter. Find the and confidence intervals for the mean zinc concentration in the river. Assume that the population standard deviation is gram per milliliter. Solution:
The point estimate ofis . The -value leaving an area of to the right, and therefore an area of to the left, is (from table). Hence, the confidence interval is which reduces to
. To find a confidence interval, we find the -value leaving an area of to the right and to the left. From Table A.3 again, , and the confidence interval is: or simply
We now see that a longer interval is required to estimate
Error in Estimation
The

Error in estimating
by . (Walpole et al., 2017).
Theorem:
If
is used as an estimate of , we can be confident that the error will not exceed .
In the previous example, we are
Sample Size Determination
Frequently, we wish to know how large a sample is necessary to ensure that the error in estimating
Theorem:
If
is used as an estimate of , we can be confident that the error will not exceed a specified amount when the sample size is
When solving for the sample size,
Strictly speaking, the formula in the theorem above is applicable only if we know the variance of the population from which we select our sample. Lacking this information, we could take a preliminary sample of size
Example: Sample Size Calculation
How large a sample is required if we want to be
confident that our estimate of in the previous example is off by less than ? Solution:
The population standard deviation is. Then, by theorem above, Therefore, we can be
confident that a random sample of size will provide an estimate differing from by an amount less than .
One-Sided Confidence Bounds
The confidence intervals and resulting confidence bounds discussed thus far are two-sided (i.e., both upper and lower bounds are given). However, there are many applications in which only one bound is sought. For example, if the measurement of interest is tensile strength, the engineer receives better information from a lower bound only. This bound communicates the worst-case scenario. On the other hand, if the measurement is something for which a relatively large value of
One-sided confidence bounds are developed in the same fashion as two-sided intervals. However, the source is a one-sided probability statement that makes use of the Central Limit Theorem:
One can then manipulate the probability statement much as before and obtain
Similar manipulation of
As a result, the upper and lower one-sided bounds follow.
Definition:
If
is the mean of a random sample of size from a population with variance , the one-sided confidence bounds for are given by: Upper one-sided bound:
Lower one-sided bound:
Example: Psychological Testing
In a psychological testing experiment, 25 subjects are selected randomly and their reaction time, in seconds, to a particular stimulus is measured. Past experience suggests that the variance in reaction times to these types of stimuli is
and that the distribution of reaction times is approximately normal. The average time for the subjects is seconds. Give an upper bound for the mean reaction time. Solution:
The upperbound is given by Hence, we are
confident that the mean reaction time is less than seconds.
Concept of a Large-Sample Confidence Interval
Often statisticians recommend that even when normality cannot be assumed,
may be used. This is often referred to as a large-sample confidence interval. The justification lies only in the presumption that with a sample as large as 30 and the population distribution not too skewed,
Example: SAT Mathematics Scores
Scholastic Aptitude Test (SAT) mathematics scores of a random sample of
high school seniors in the state of Texas are collected, and the sample mean and standard deviation are found to be and , respectively. Find a confidence interval on the mean SAT mathematics score for seniors in the state of Texas. Solution:
Since the sample size is large, it is reasonable to use the normal approximation. Using a table, we find. Hence, a confidence interval for is which yields
.
Standard Error of a Point Estimate
We have made a rather sharp distinction between the goal of a point estimate and that of a confidence interval estimate. The former supplies a single number extracted from a set of experimental data, and the latter provides an interval that is reasonable for the parameter, given the experimental data; that is,
These two approaches to estimation are related to each other. The common thread is the sampling distribution of the point estimator. Consider, for example, the estimator
Thus, the standard deviation of
For
is written as
The important point is that the width of the confidence interval on
Definition:
The confidence limits on
are:
Again, the confidence interval is no better (in terms of width) than the quality of the point estimate, in this case through its estimated standard error. Computer packages often refer to estimated standard errors simply as “standard errors.”
As we move to more complex confidence intervals, there is a prevailing notion that widths of confidence intervals become shorter as the quality of the corresponding point estimate becomes better, although it is not always quite as simple as we have illustrated here. It can be argued that a confidence interval is merely an augmentation of the point estimate to take into account the precision of the point estimate.
Two Samples: Estimating the Difference between Two Means
If we have two populations with means
We can expect the sampling distribution of
will fall between
Substituting for
which leads to the following
Confidence Interval for
, and Known: If
and are means of independent random samples of sizes and from populations with known variances and , respectively, a confidence interval for is given by where
is the -value leaving an area of to the right.
The degree of confidence is exact when samples are selected from normal populations. For nonnormal populations, the Central Limit Theorem allows for a good approximation for reasonable size samples.
The Experimental Conditions and the Experimental Unit
For the case of confidence interval estimation on the difference between two means, we need to consider the experimental conditions in the data-taking process. It is assumed that we have two independent random samples from distributions with means
Example:
A study was conducted in which two types of engines,
and , were compared. Gas mileage, in miles per gallon, was measured. Fifty experiments were conducted using engine type and experiments were done with engine type . The gasoline used and other conditions were held constant. The average gas mileage was miles per gallon for engine A and miles per gallon for engine . Find a confidence interval on , where and are population mean gas mileages for engines and , respectively. Assume that the population standard deviations are and for engines and , respectively. Solution:
The point estimate ofis . Using , we find from a table. Hence, with substitution in the formula above, the confidence interval is or simply
.
This procedure for estimating the difference between two means is applicable if
Variances Unknown but Equal
Consider the case where
The two random variables
have chi-squared distributions with
has a chi-squared distribution with
has the
Definiton:
The Pooled Estimate of Variance
is defined as:
Substituting
Using the
where
After the usual mathematical manipulations, the difference of the sample means
Confidence Interval for
, but Both Unknown: If
and are the means of independent random samples of sizes and , respectively, from approximately normal populations with unknown but equal variances, a confidence interval for is given by where
is the pooled estimate of the population standard deviation and is the -value with degrees of freedom, leaving an area of to the right.
Example:
The article “Macroinvertebrate Community Structure as an Indicator of Acid Mine Pollution,” published in the Journal of Environmental Pollution, reports on an investigation undertaken in Cane Creek, Alabama, to determine the relationship between selected physiochemical parameters and different measures of macroinvertebrate community structure. One facet of the investigation was an evaluation of the effectiveness of a numerical species diversity index to indicate aquatic degradation due to acid mine drainage. Conceptually, a high index of macroinvertebrate species diversity should indicate an unstressed aquatic system, while a low diversity index should indicate a stressed aquatic system. Two independent sampling stations were chosen for this study, one located downstream from the acid mine discharge point and the other located upstream. For
monthly samples collected at the downstream station, the species diversity index had a mean value and a standard deviation , while monthly samples collected at the upstream station had a mean index value and a standard deviation . Find a confidence interval for the difference between the population means for the two locations, assuming that the populations are approximately normally distributed with equal variances. Solution:
Letand represent the population means, respectively, for the species diversity indices at the downstream and upstream stations. We wish to find a confidence interval for . Our point estimate of is The pooled estimate,
, of the common variance, , is Taking the square root, we obtain
. Using , we find in Table A.4 that for degrees of freedom. Therefore, the confidence interval for is which simplifies to
.
Interpretation of the Confidence Interval
For the case of a single parameter, the confidence interval simply provides error bounds on the parameter. Values contained in the interval should be viewed as reasonable values given the experimental data. In the case of a difference between two means, the interpretation can be extended to one of comparing the two means. For example, if we have high confidence that a difference
Equal Sample Sizes
The procedure for constructing confidence intervals for
Unknown and Unequal Variances
Let us now consider the problem of finding an interval estimate of
which has approximately a
Since
where
Confidence Interval for
, and Both Unknown: If
and and and are the means and variances of independent random samples of sizes and , respectively, from approximately normal populations with unknown and unequal variances, an approximate confidence interval for is given by where
is the -value with degrees of freedom, leaving an area of
to the right.
Note that the expression for
or
For example, in the case where
Example:
A study was conducted by the Department of Zoology at the Virginia Tech to estimate the difference in the amounts of the chemical orthophosphorus measured at two different stations on the James River. Orthophosphorus was measured in milligrams per liter. Fifteen samples were collected from station 1, and 12 samples were obtained from station 2. The 15 samples from station 1 had an average orthophosphorus content of
milligrams per liter and a standard deviation of milligrams per liter, while the 12 samples from station 2 had an average content of milligrams per liter and a standard deviation of milligram per liter. Find a confidence interval for the difference in the true average orthophosphorus contents at these two stations, assuming that the observations came from normal populations with different variances. Solution:
For station 1, we have, , and . For station 2, , , and . We wish to find a confidence interval for . Since the population variances are assumed to be unequal, we can only find an approximate
confidence interval based on the -distribution with degrees of freedom, where Our point estimate of
is Using
, we find in Table A.4 that for degrees of freedom. Therefore, the confidence interval for is which simplifies to
. Hence, we are confident that the interval from to milligrams per liter contains the difference of the true average orthophosphorus contents for these two locations.
When two population variances are unknown, the assumption of equal variances or unequal variances may be precarious. In Section 10.10, a procedure will be introduced that will aid in discriminating between the equal variance and the unequal variance situation.